






2025年6月14日,谷歌确认其Google Cloud服务在6月12日晚至6月13日凌晨发生了一次大规模宕机事件,持续时间超过三小时。此次故障影响了全球数百万用户,并波及多个依赖Google Cloud的第三方平台。根据IT之家的报道,此次宕机的根本原因在于API管理问题,具体表现为无效数据引发的API管理平台失效。
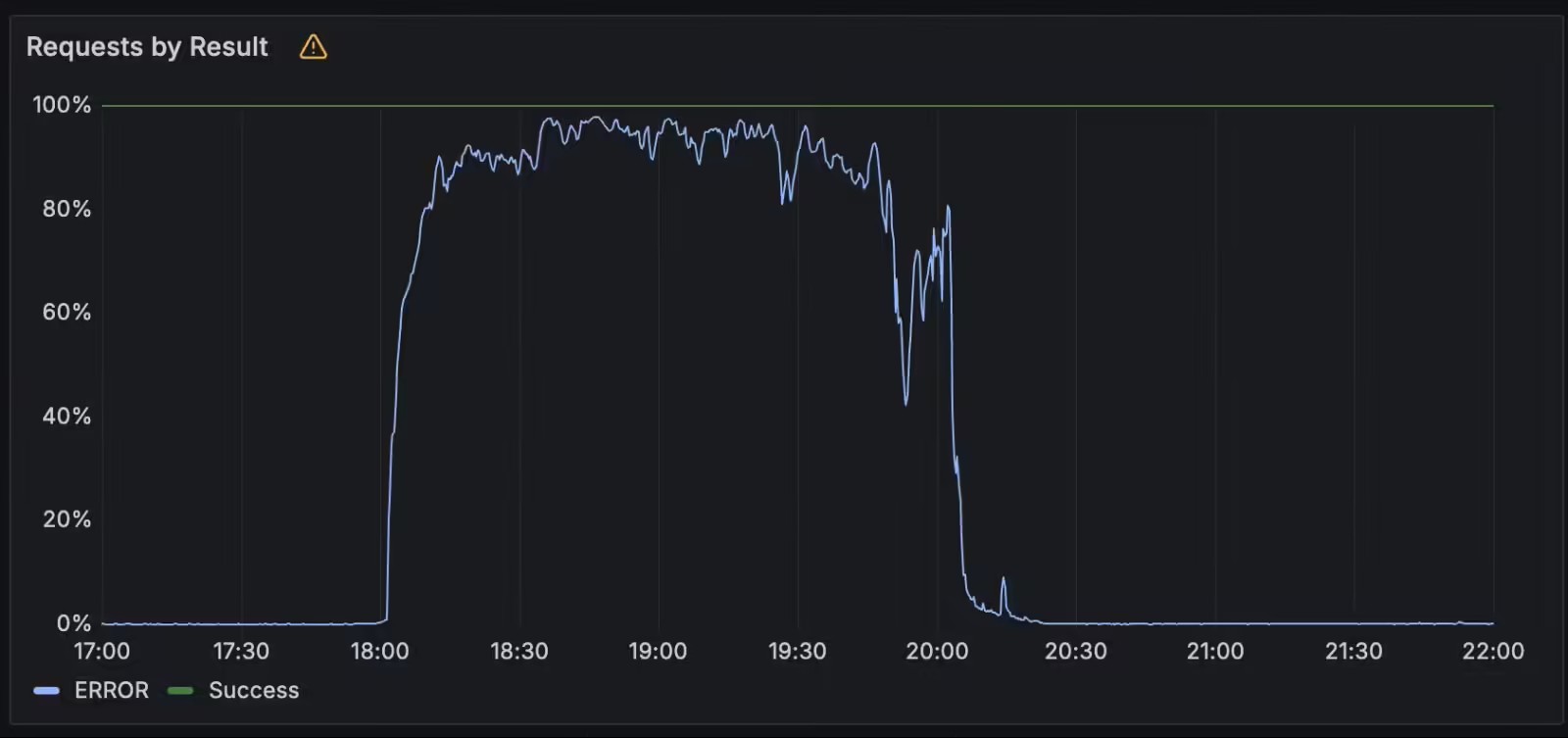
事件回顾:核心服务中断,影响广泛
北京时间6月12日22点49分到6月13日凌晨1点49分,包括Gmail、Google Calendar、Google Docs、Google Drive和Google Meet等在内的多项谷歌核心服务无法正常使用。这次宕机不仅影响了谷歌自身的服务,还波及了众多第三方平台,如Spotify、Discord、Snapchat、NPM和Firebase Studio等知名应用和服务。
谷歌官方解释称,问题的根源在于API管理平台因无效数据而失效,由于缺乏有效的测试和错误处理机制,未能及时发现并修复问题。尽管大多数地区在两小时内恢复,但us-central1区域的配额策略数据库超载,导致恢复时间延长。
连锁反应:多平台受影响,Cloudflare部分服务中断
此次宕机事件不仅限于谷歌内部的服务,还对依赖Google Cloud的其他平台造成了重大影响。例如,Cloudflare的部分服务也因依赖Workers KV键值存储系统而中断。虽然此次宕机并非由安全事件引发,也未造成数据丢失,但它暴露了底层存储基础设施存在的问题。该基础设施部分由第三方云服务商提供(虽未明确指出,但确认与Google Cloud相关)。
为了减少对外部服务的依赖,Cloudflare计划将KV核心存储迁移至自有的R2对象存储系统,以提高系统的稳定性和可靠性。
行业反思:自动化配额更新带来的挑战
谷歌进一步解释,此次宕机是由于API管理系统的一次无效自动化配额更新,导致外部API请求被拒绝。这一事件揭示了自动化配额更新机制中存在的潜在风险,特别是在高负载情况下,可能导致关键服务中断。因此,未来需要更加重视此类机制的设计和测试,确保其能够在实际操作中稳定运行。
应对措施:提升测试与错误处理机制
面对此次事件,谷歌强调了加强测试和错误处理机制的重要性。未来的改进方向包括增强API管理平台的健壮性,增加冗余设计,以及优化自动化流程中的监控和预警机制。通过这些措施,可以有效预防类似事件的发生,确保服务的连续性和稳定性。
用户反馈与市场反应
此次宕机事件引起了用户的广泛关注和讨论。许多用户在社交媒体上表达了对服务中断的不满,并呼吁谷歌采取更有效的措施来防止类似事件的再次发生。此外,一些企业客户也表示,他们正在重新评估对单一云服务提供商的依赖程度,考虑采用多云策略来分散风险。
总结与展望
此次谷歌云服务的大规模宕机事件提醒我们,即使是技术巨头,在面对复杂的系统架构时也可能遇到不可预见的问题。对于云计算服务提供商而言,必须不断提升系统稳定性和容错能力,同时加强应急响应机制,以应对可能发生的各种突发情况。而对于用户来说,选择可靠的云服务供应商,并制定相应的应急预案,是确保业务连续性的关键。
在未来的发展中,如何平衡技术创新与系统稳定性,将是所有云计算服务提供商需要共同面对的重要课题。通过不断优化技术架构、完善测试流程、强化监控和预警机制,才能为用户提供更加可靠、高效的服务体验。这不仅是对谷歌的要求,也是整个行业的共同目标。

 鲁ICP备20031633号-2
鲁ICP备20031633号-2